Benefits of Artificial Intelligence: How it Contributes to Our Society and Economy

Updated: 2026
Artificial intelligence is now an integral part of everyday business operations. Companies use it to automate processes, analyze data, and enhance customer interactions. What began as a research topic has become a practical tool across industries.
Many organizations already rely on AI in at least one business function. The focus has shifted from experimentation to real business value. This article explains the most important benefits of AI and where they create measurable impact.
Read moreGenerative AI Trends: 2025 Market Report

AI models are only as good as the data they learn from. But what does this mean for AI in 2025? With the global AI training dataset market booming estimated at $2.8 billion in 2024 and projected to reach ~$9.6 billion by 2029 the demand for high-quality data has never been greater. High-quality labeled data is increasingly recognized as the backbone of successful AI, with the data labeling market alone expected to grow from $0.8 billion in 2022 to $3.6 billion by 2027.
But what exactly is driving this growth, and how are industry leaders responding? Key improvements on the horizon include more accurate and efficient annotation techniques, greater use of synthetic data to supplement real examples, robust human-in-the-loop oversight for validation, compliance with emerging AI regulations on data quality, and new data management tools that boost pipeline integrity.
Read moreError Handling in Data Annotation Pipelines

Imagine teaching a child to recognize animals using flashcards—but what if half the labels were wrong? That’s the high-stakes reality of data annotation, the invisible scaffolding holding up today’s AI. At its core, annotation is about teaching machines to “see” by labeling raw data—photos, text, audio—with meaningful tags. But here’s the catch: this deceptively simple task is riddled with pitfalls. A misplaced label or biased tag doesn’t just confuse an algorithm—it can warp predictions, bake in discrimination, or even lead to life-or-death mistakes in fields like healthcare or self-driving cars.
Read moreAutomated Data Validation Frameworks

Data has become the lifeblood of modern businesses, but here’s the catch: how do you trust a tsunami of numbers, spreadsheets, and sensor readings flooding your systems daily? Picture a librarian trying to manually check every book in a skyscraper-sized library – that’s traditional data validation trying to keep up with today’s data deluge.
The truth is, manual checks worked when data moved at a bicycle’s pace. Now? It’s a supersonic jet. Automated validation tools have become essential infrastructure. Imagine teaching machines to spot errors faster than a caffeine-fueled analyst, scale across cloud databases without breaking a sweat, and adapt as your data evolves.
Read moreDataset Balancing Techniques

Imagine teaching a computer to spot a needle in a haystack – except the haystack is the size of a football field, and there are only three needles hidden inside. This is the frustrating reality of data imbalance in machine learning, where one category (like those rare “needles”) gets drowned out by overwhelming amounts of other data. It’s like training a security guard to spot thieves in a crowd where 99% of people are innocent—without special techniques, they’ll just wave everyone through and call it a day.
Here’s the problem: most machine learning algorithms are optimists. They aim for high accuracy by favoring the majority class, completely missing the subtle patterns in the underrepresented group. Take fraud detection—if only 0.1% of transactions are fraudulent, a model might lazily label everything as “safe” and still boast 99.9% accuracy. Meanwhile, actual fraud slips through undetected, costing millions.
Read moreBest Practices for Training Data Quality Control

Real-world data is messy. The magic happens when we clean it up, fill gaps, and create systems to keep it trustworthy. In the next sections, we’ll break down the messy realities of data gremlins (missing values, biased samples, inconsistent labels), share battle-tested strategies to tackle them, and walk through how to bake quality checks into every step of your workflow. Spoiler: It’s less about fancy tools and more about smart, consistent habits. Ready to dig in?
Read moreOvercoming Bottlenecks in High-Volume Image and Video Annotation

In artificial intelligence, the quality of training data is the lifeblood of how well models perform. Take image and video annotation, for instance. Here, precision isn’t a luxury; it’s what determines whether an AI system can genuinely “see” the world or stumble blindly through pixelated guesswork.
Jan Mentken, Head of Solutions at clickworker, puts it clearly: “We had a client who initially tried using AI for their annotation needs, but the results just weren’t cutting it. They came to us because they needed that human touch to achieve the level of quality required to train their model effectively.” His story hits like a reality check: for all its dazzling advances, AI still leans heavily on human judgment when it comes to nuanced, high-stakes tasks.
Tackling massive annotation projects isn’t just about throwing manpower at pixels. It’s a dance of meticulous planning and ironclad quality checks. At clickworker, the focus isn’t on speed for speed’s sake. Instead, teams zero in on crafting annotations so precise they become the invisible scaffolding for AI systems people can actually trust. After all, when machines “see,” they’d better see things right – whether it’s spotting a tumor in an X-ray or recognizing a pedestrian at dusk.
Read moreFrom Pixels to Purpose – 9 Helpful Image Annotation Tools

Image annotation tools are quietly behind some of the biggest changes in how automated machines interact with us – revolutionizing everything from self-driving cars to medical diagnostics. But what makes these tools so important and how do they work? In this blog post, we will introduce you to nine picture annotation tools and take a closer look at the different types of image annotation.
Read moreMedical Data Annotation: The Key to Advancing Diagnostic AI
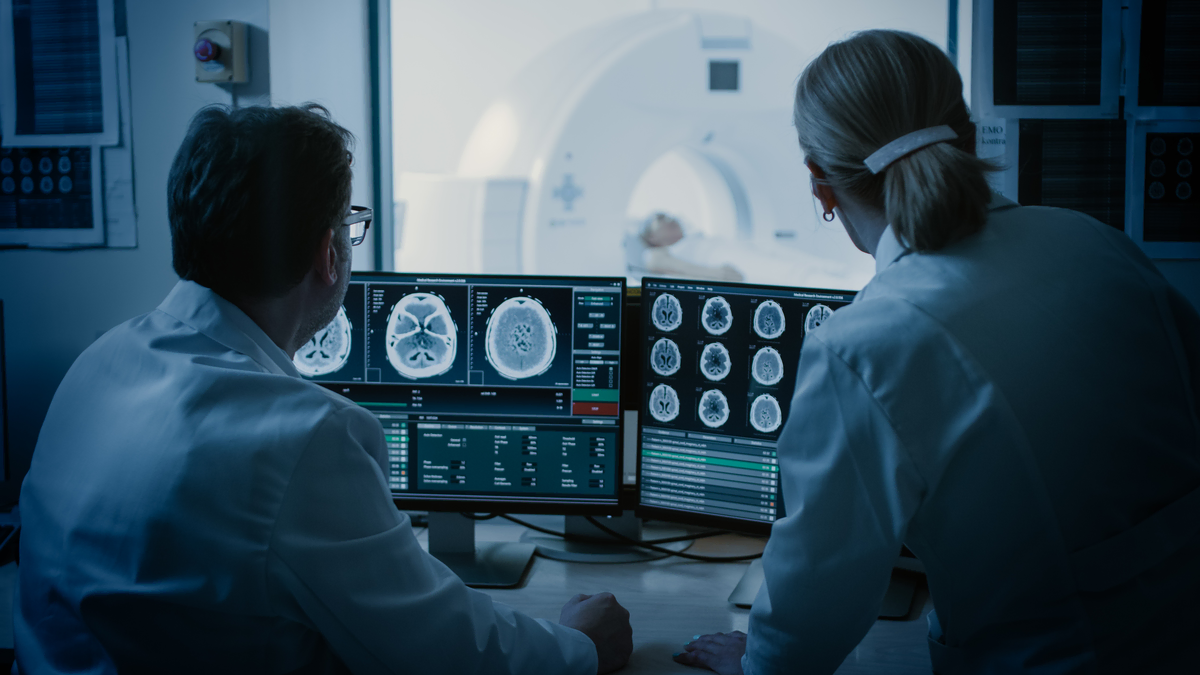
The global market for healthcare and medical data annotation tools is set to rise to $1.1 billion by 2032, showing an impressive annual growth rate of 23.85% from 2024 to 2032, according to the IMARC Group’s Healthcare Data Annotation Tools Market Report.
What’s driving this impressive growth? There are a few key reasons. First, we are seeing a surge in the use of artificial intelligence (AI) and machine learning (ML) in healthcare. Then there’s the fact that we’re generating huge amounts of data every day.
Additionally, there have been significant advancements in medical imaging technologies, along with improved access to high-quality image datasets.
The rising demand for telemedicine services highlights the importance of AI training data, which enhances diagnostic accuracy, personalized patient care, supports remote monitoring, and automates administrative tasks, ultimately improving the efficiency of remote healthcare delivery.
All these trends are driving the medical data annotation market forward, showing just how important these technologies are for improving healthcare delivery and patient outcomes.
Let’s look at why medical data annotation is important and how AI training data and image and photo datasets are transforming healthcare for the better.
Read moreLLM Hallucinations – Causes and Solutions

The precision and reliability of Artificial Intelligence (AI) are crucial, especially with large language models (LLMs). A common issue with these models is the phenomenon of “LLM hallucinations”. This term describes the tendency of language models to generate information not based on reality. This can range from incorrect facts to entirely fabricated stories.
LLM hallucinations pose a serious challenge as they can undermine the credibility and reliability of AI systems. They mainly arise due to insufficient or faulty training data, lack of contextualization, and the models’ excessive creativity. This problem affects both the developers of LLMs and businesses and end-users who rely on precise and reliable AI results.
To prevent these hallucinations and improve the quality of AI models, the provision of high-quality AI training data is crucial. This is where we, clickworker, come into play. We provide customized training data solutions and ensure the quality and accuracy of the data through crowdsourcing techniques and human review. By integrating these high-quality data, LLMs can work more precisely and reliably, leading to better results and increased user trust.
In this blog post, we will explore the causes and impacts of LLM hallucinations and show how clickworker’s services help address these challenges and improve the quality of language models.
Read more
